
Meta heeft Llama 3 aangekondigd, de opvolger van het zeer succesvolle open-source model Llama 2. Samen met de nieuwe LLM debuteert Meta AI, volgens het bedrijf een van de beste AI-assistenten ter wereld.
Llama 3 lanceert met twee modellen: het compacte Llama 3-8B (8 miljard parameters), dat op minder imposante hardware te draaien is, en Llama 3-70B. Dat is er een minder dan Llama 2, dat een 7B-, 13B- en 70B-variant kende. Het aantal parameters heeft een grote invloed op de accuratesse van een model, evenals de systeemeisen. De modellen zijn al beschikbaar op Amazon SageMaker. Latere releases volgen op Databricks, Google Cloud, Hugging Face, Kaggle, IBM watsonx, Azure, Nvidia NIM en Snowflake.
Meta zegt opnieuw open-source te willen omarmen om de eigen Llama-modellen te ontwikkelen. De weg naar deze opstelling is en blijft een unieke. Llama’s eerste model lekte begin 2023 nadat het enkel voor onderzoekers bestemd was, waarna Meta besloot om Llama 2 direct te lanceren als open-source model. Het staat in schril contrast met partijen als OpenAI, dat alle GPT-4-modellen achter slot en grendel ontwikkelt en beschikbaar stelt.
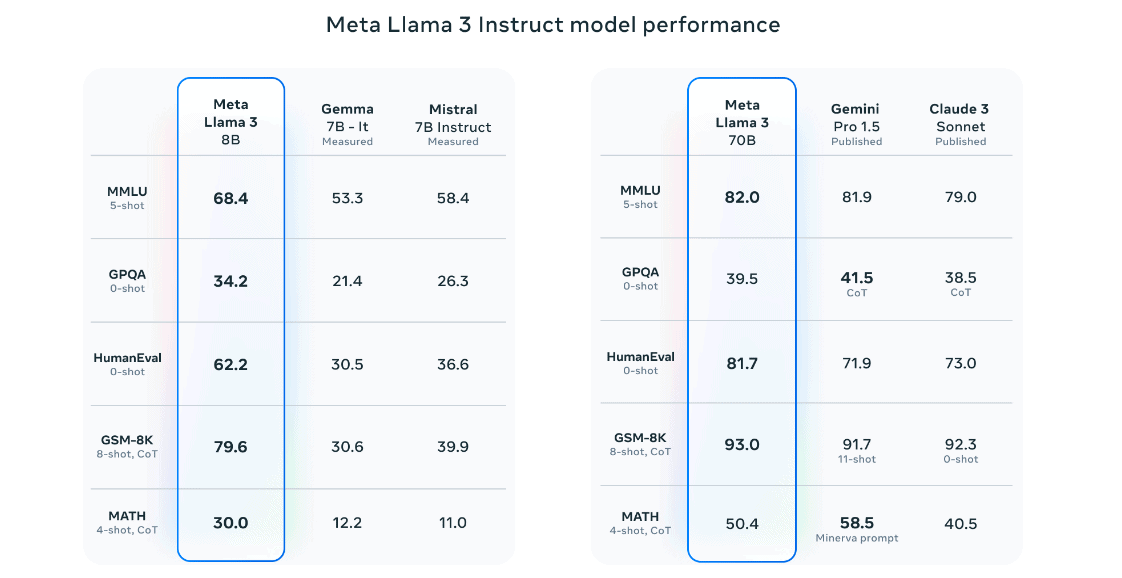
Indrukwekkende prestaties
Momenteel laten AI-benchmarks een continu verschuivend beeld zien. Modellen van Google, OpenAI, Anthropic, Mistral en Meta weten elk op bepaalde vlakken uit te blinken, hoewel de precieze testmethode en de gekozen modellen veelal verschilt. Llama 3-8B lijkt echter goed uit de verf te komen in bekende benchmarks, terwijl de 70B-variant zoals verwacht een schep daarbovenop doet. Hoe hoger de score, hoe accurater, menselijker of beter redenerend een model overkomt.
Om Llama 3 naar wens aan te passen, kunnen ontwikkelaars gebruikmaken van verschillende tools. Zodra de modellen beschikbaar zijn op de eerder genoemde platformen bestaat er een groot aantal training-, fine-tuning-, RAG– en inferencing-opties van derden. Met andere woorden: aan Llama 3 kunnen ontwikkelaars zelf data koppelen om specifieke toepassingen mogelijk te maken.
Zelf biedt Meta geüpdatete componenten als Llama Guard 2 en Cybersec Eval 2, naast het nieuwe Code Shield. Laatstgenoemde kan onveilige programmeercode wegfilteren uit AI-outputs.
Ten opzichte van Llama 2 is versie 3 een stuk sneller, maar ook efficiënter. Zo gebruikt Llama 3 een tokenizer met een woordenschat van 128.000 tokens en encodeert het talen veel efficiënter dan voorheen: Llama 2 kende ‘slechts’ 32.000 tokens. Dit verschil betekent dat het nieuwe AI-model complexere termen beter kan vatten. Wel kan de trainingstijd hierdoor toenemen.
Meta AI: nog niet in Europa
Naast het Llama 3-model presenteert Meta direct een applicatie die erop draait: Meta AI. Deze chatbot kan in een eigen venster gebruikt worden of in feeds, chat en zoekopdrachten binnen Meta-apps. Althans, voor gebruikers in Amerika, Australië, Canada, Ghana, Jamaica, Malawi, Nieuw-Zeeland, Nigeria, Pakistan, Singapore, Zuid-Afrika, Oeganda, Zambia en Zimbabwe.
Meta AI verschijnt nog niet in Europa dus, een bekend verschijnsel bij dergelijke AI-chatbots. Zo verscheen Google Bard (nu hernoemd naar Gemini) pas maanden na de initiële release in andere landen binnen de EU. De reden lijkt te zijn dat Europese regelgeving strenger toeziet op onveilig AI-gedrag en minder onduidelijkheid over trainingsdata duldt, hoewel de regels de afgelopen maanden continu zijn veranderd.
Hoe dan ook oogt Meta AI als een volwaardige tegenhanger voor ChatGPT en Google Gemini. De aanpak is ook hier multimodaal, waardoor de chatbot afbeeldingen kan produceren of analyseren naast tekstprompts. Meta AI is daarnaast geïntegreerd in Facebook, Instagram, WhatsApp en Messenger, vergelijkbaar met de aanpak die Microsoft kiest voor het eigen Copilot-aanbod.
Stip aan de horizon: Megalodon
Er valt vanuit Meta nog meer te melden. Zo stellen onderzoekers van het bedrijf samen met collega’s aan de University of Southern California een nieuw AI-model voor: Megalodon. Deze LLM moet hardnekkige problemen van huidige AI-modellen oplossen. De Transformer, de fundamentele architectuur achter generatieve AI zoals we het nu kennen, kent een aantal beperkingen. Denk hierbij aan hoge systeemeisen en een beperkte hoeveelheid aan inputs die tegelijk doorgevoerd kunnen worden.
Met Megalodon zou het mogelijk zijn om extreem veel tokens in de context window te plaatsen, waardoor AI-modellen veel meer informatie tot zich kunnen nemen dan tegenwoordig. Let wel, dat is een ontwikkeling waar meerdere partijen mee bezig zijn. Google claimt zelfs een oneindige invoer voor AI mogelijk te maken met “Infini-attention“.
In het geval van Megalodon kiest Meta voor Moving Average Equipped Gate Attention (MEGA), dat uit 2022 afstamt. Met deze techiek verplaatst het model de aandacht geleidelijk door een input, maar op een manier die veel zuiniger omgaat met computergeheugen dan Transformers. Het is een AI-pad dat Meta hiermee bewandelt dat afwijkt van bijvoorbeeld Microsoft, dat tot nu toe vooral probeert om modellen kleiner te krijgen.